

我们很高兴地宣布,我们近期发表的期刊论文“重新审视图神经网络在结构攻击下的抗逆性:一种简单且快速的方法”已于2025年12月在《IEEE Transactions on Information Forensics and Security》(TIFS)上发表。论文由本院与香港理工大学、上海交通大学、美国加利福尼亚大学欧文分校合作完成:
- Xing Ai, Yulin Zhu, Yu Zheng, Gaolei Li, Jianhua Li, Kai Zhou, “Revisiting Adversarial Robustness of GNNs Against Structural Attacks: A Simple and Fast Approach” in IEEE Transactions on Information Forensics and Security, vol. 21, pp. 446-459, 2025, doi: 10.1109/TIFS.2025.3641816.
论文链接: https://ieeexplore.ieee.org/document/11311611
论文摘要
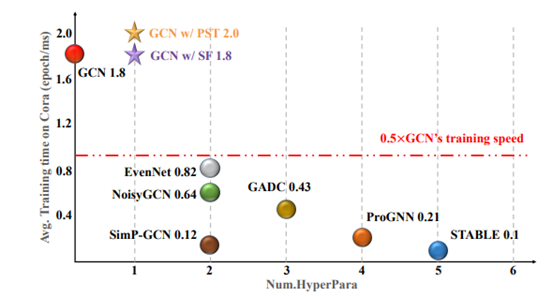
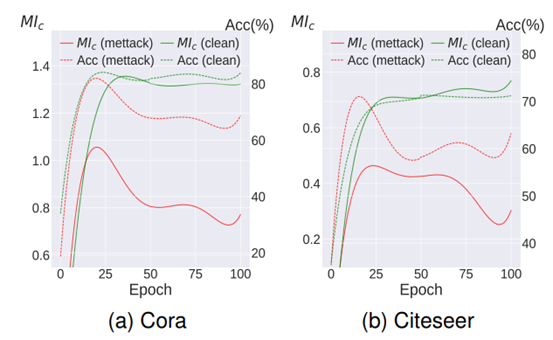
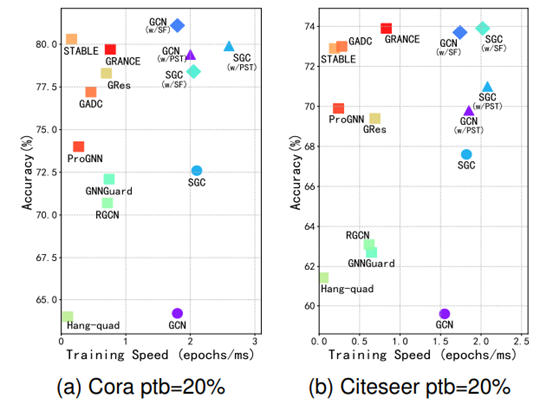
为了抵御针对图的对抗性结构攻击,我们从互信息的角度来分析这些攻击,并发现了“成对效应”。这一效应表明,当这些图神经网络接收到与给定节点属性相结合的修改后的结构作为训练输入时,结构攻击会显著降低受害图神经网络的性能。因此,我们提出了一种新颖的防御策略,通过在受害图神经网络的训练过程中破坏修改结构与节点属性的配对关系,使结构攻击无效,我们将其实称为“破坏成对效应”。为了实现这一理念,我们提出了两种简单但有效的训练策略:结构微调(SF)和渐进式结构训练(PST),它们分别通过节点属性预训练、结构微调和渐进式结构训练来破坏成对效应。与现有的鲁棒图神经网络相比,我们的策略避免了耗时的技术,从而提高了图神经网络的鲁棒性,同时加快了训练速度。此外,这些策略能够轻松应用于各种常见的图神经网络(GNN),包括稳健的 GNN 变体,使其能够高度适应不同的模型和应用。我们对所提出的训练策略进行了理论分析,并在各种数据集上进行了大量实验以证明其有效性。
本文的数据集和代码:https://github.com/Xing-Ai1003/Revisiting-Adversarial-Robustness-of-GNNs
研究团队成员
香港珠海学院
- Dr. Zhu Yulin,资讯科学学系助理教授
香港理工大学
- Dr. Ai Xing,计算科学系博士生
Prof. Zhou Kai,计算科学系助理教授
上海交通大学
- Prof. Li Gaolei, 电子信息与电气工程学院副教授
Prof. Li Jianhua, 电子信息与电气工程学院正教授
美国加利福尼亚大学欧文分校
- Dr. Zheng Yu, 电子信息与计算机科学学院博士后研究员
关于学术论文的照片




{kind=link}
{kind=link}